20 min to read
자바 ORM 표준 JPA 프로그래밍
14. 컬렉션과 부가 기능

JPA에서 지원하는 컬렉션의 종류와 부가 기능은 다음과 같다.
- 컬렉션 : 다양한 컬렉션과 특징을 설명한다.
- 컨버터 : 엔티티의 데이터를 변환해서 데이터베이스에 저장한다.
- 리스너 : 엔티티에서 발생한 이벤트를 처리한다.
- 엔티티 그래프 : 엔티티를 조회할 때 연관된 엔티티들을 선택해서 함께 조회한다.
컬렉션
JPA와 컬렉션
하이버네이트는 엔티티를 영속 상태로 만들 때 컬렉션 필드를 하이버네이트에서 준비한 컬렉션으로 감싸서 사용한다.
- JPA 컬렉션 사용
@Entity
public class Team {
@Id
private String id;
@OneToMany
@JoinColumn
private Collection<Member> members = new ArrayList<Member>();
...
}
위와 같은 Member 컬렉션을 필드로 갖고 있는 Team을 영속 상태로 만들자.
Team team = new Team();
System.out.println("before persist = " + team.getMembers().getClass());
em.persist(team);
System.out.println("after persist = " + team.getMembers().getClass());
출력 결과는 다음과 같다.
before persist = class java.util.ArrayList
after persist = class org.hibernate.collection.internal.PersistentBag
원래 ArrayList 타입이었던 컬렉션이 엔티티를 영속 사태로 만든 직후에 하이버네이트가 제공하는 PersistentBag 타입으로 변경된다.
하이버네이트는 컬렉션을 효율적으로 관리하기 위해 엔티티를 영속 상태로 만들 때 원본 컬렉션을 감싸고 있는 내장 컬렉션을 생성하여 이 내장 컬렉션을 사용하도록 참조를 변경한다. 래퍼 컬렉션이라고도 불린다.
하이버네이트는 이러한 특징 때문에 컬렉션을 사용할 때 아래와 같이 즉시 초기화해서 사용하는 것을 권장한다.
Collection<Member> members = new ArrayList<Member>();
- 하이버네이트 내장 컬렉션과 특징
| 컬렉션 인터페이스 | 내장 컬렉션 | 중복 허용 | 순서 보관 |
|---|---|---|---|
| Collection, List | PersistenceBag | O | X |
| Set | PersistenceBag | X | X |
| List + @OrderColumn | PersistentList | O | O |
Collection, List
ArrayList로 초기화한다.
@Entity
public class Parent {
@Id @GeneratedValue
private Long id;
@OneToMany
@JoinColumn
private Collection<CollectionChild> collection = new ArrayList<CollectionChild>();
@OneToMany
@JoinColumn
private List<ListChild> list = new ArrayList<ListChild>();
...
}
Collection, List는 중복을 허용하므로 객체를 추가하는 add() 메소드는 내부에서 어떤 비교도 하지 않고 항상 true를 반환한다.
같은 엔티티가 있는지 찾거나 삭제할 때는 equals() 메소드를 사용한다.
List<Comment> comments = new ArrayList<Comment>();
...
// 단순히 추가만, 결과는 항상 true. 지연 로딩 발생 X
boolean result = comments.add(data)
comments.contains(comment); // equals 비교, 지연 로딩 발생
comments.remove(comment); // equals 비교, 지연 로딩 발
Collection, List는 엔티티를 추가할 때 중복된 엔티티가 있는지 비교할 필요없이 저장만 하면 된다. 따라서 엔티티를 추가해도 지연 로딩된 컬렉션을 초기화하지 않는다.
Set
HashSet으로 초기화한다.
@Entity
public class Parent {
@OneToMany
@JoinColumn
private Set<SetChild> set = new HashSet<SetChild>();
...
}
HashSet은 중복을 허용하지 않으므로 add() 메소드로 객체를 추가할 때 마다 equals() 메소드로 같은 객체가 있는지 비교한다.
같은 객체가 없으면 객체를 추가하고 true를 반환하고, 있어서 추가에 실패하면 false를 반환한다.
참고로 HashSet은 해시 알고리즘을 사용하므로 hashcode() 도 함께 사용해서 비교한다.
Set<Comment> comments = new HashSet<Comment>();
...
boolean result = comments.add(data); // hashcode + equals 비교, 지연 로딩 발생
comments.contains(comment); // hashcode + equals 비교, 지연 로딩 발생
comments.remove(comment); // hashcode + equals 비교, 지연 로딩 발생
Set은 엔티티를 추가할 때 마다 중복된 엔티티가 있는지 비교해야 하기 때문에, 지연 로딩된 컬렉션을 초기화한다.
List + @OrderColumn
List 인터페이스에 @OrderColumn을 추가하면 순서가 있는 특수한 컬렉션으로 인식한다. 순서가 있다는 의미는 데이터베이스에 순서 값을 저장해서 조회할 때 사용한다는 의미이다.
하이버네이트는 내부 컬렉션인 PersistentList를 사용한다.
@OrderColumn은 데이터베이스의 순서용 컬럼을 매핑하여 관리한다.
@Entity
public class Board {
@Id @GeneratedValue
private Long id;
private String title;
private String content;
@OneToMany(mappedBy = "board")
@OrderColumn(name = "POSITION")
private List<Comment> comments = new ArrayList<Comment>();
...
}
@Entity
public class Comment {
@Id @GeneratedValue
private Long id;
private String comment;
@ManyToOne
@JoinColumn(name = "BOARD_ID")
private Board baord;
...
}
순서가 있는 컬렉션은 데이터베이스에 순서 값도 함께 관리한다. 위 코드에서는 @OrderColumn의 name 속성에 POSITION 컬럼에 순서 값을 저장한다.
그런데 Board.comment 컬렉션은 Board 엔티티에 있지만 테이블의 일대다 관계의 특성상 위치 값은 다(N) 쪽에 저장해야 한다. 따라서 실제 POSITION 컬럼은 COMMENT 테이블에 매핑된다.
- 사용 예제
Board board = new Board("제목1", "내용1");
em.persist(board);
Comment comment1 = new Comment("댓글1");
comment1.setBoard(board);
board.getComments().add(comment1); // POSITION 0
em.persist(comment1);
Comment comment2 = new Comment("댓글2");
comment2.setBoard(board);
board.getComments().add(comment2); // POSITION 1
em.persist(comment2);
Comment comment3 = new Comment("댓글3");
comment3.setBoard(board);
board.getComments().add(comment3); // POSITION 2
em.persist(comment3);
Comment comment4 = new Comment("댓글4");
comment4.setBoard(board);
board.getComments().add(comment4); // POSITION 3
em.persist(comment4);
하지만 @OrderColumn은 실무에서 사용하기에는 단점이 많다. @OrderBy를 사용하자.
@OrderColumn의 단점
- @OrderColumn을 Board 엔티티에서 매핑하므로 Comment는 POSITION의 값을 알 수 없다. 그래서 Comment를 INSERT할 때는 POSITION 값이 저장되지 않는다. POSITION은 Board.comments의 위치 값이므로, 이 값을 사용해서 POSITION의 값을 UPDATE 하는 SQL이 추가로 발생한다.
- List를 변경하면 연관된 많은 위치 값을 변경해야 한다.
- 댓글2를 삭제하게 되면 댓글3, 댓글4의 POSITION 값도 변경하기 위해 UPDATE SQL이 2번 추가로 실행된다.
- 중간에 POSITION 값이 없으면 조회한 List에는 null이 저장된다.
- 댓글2를 삭제 후, 다른 댓글들의 POSITION 값을 수정하지 않으면 데이터베이스의 POSITION 값은 [0,2,3]이 되어 중간에 1번 위치에 List를 조회하면 null이 저장된다. 따라서 컬렉션을 순회할 때 NPE가 발생한다.
@OrderBy
@OrderColumn은 데이터베이스의 순서용 컬럼을 매핑하여 관리한다면, @OrderBy는 데이터베이스의 ORDER BY절을 사용해서 컬렉션을 정렬한다. 따라서 순서용 컬럼을 매핑할 필요가 없다.
그리고 @OrderBy는 모든 컬렉션에 사용할 수 없다.
@Entity
public class Team {
@Id @GeneratedValue
private Long id;
private String name;
@OneToMany(mappedBy = "team")
@OrderBy("username desc, id asc")
private Set<Member> members = new HashSet<Member>();
...
}
@Entity
public class Member {
@Id @GeneratedValue
private Long id;
@Column(name = "MEMBER_NAME")
private String username;
@ManyToOne
private Team team;
}
@OrderBy를 통해 Member의 username 필드로 내림차순 정렬하고, id로 오름차순 정렬한다. @OrderBy의 값은 JPQL의 order by절 처럼 엔티티의 필드를 대상으로 한다.
Set에 @OrderBy를 적용해서 결과를 조회하면 순서를 유지하기 위해
HashSet대신 LinkedHashSet을 내부에서 사용한다.
@Converter
컨버터(converter)를 사용하면 엔티티의 데이터를 변환해서 데이터베이스에 저장할 수 있다.
@Entity
public class Member {
@Id
private String id;
private String username;
@Converter(converter=BooleanToYNConverter.class)
private boolean vip;
...
}
@Converter
public class BooleanToYNConverter implements AttributeConverter<Boolean, String> {
@Override
public String convertToDatabaseColumn(Boolean attribute) {
return (attribute != null && attribute) ? "Y" : "N";
}
@Override
public Boolean convertToEntityAttribute(String dbData) {
return "Y".equals(dbData);
}
}
boolean 타입을 데이터베이스에 저장할 때 0, 1이 아닌 Y, N으로 저장하고 싶다면 위와 같이 컨버터를 사용하면 가능하다.
@Converter를 적용해서 데이터베이스에 저장되기 직전에 BooleanToYNConverter 컨버터가 동작하게 된다.
컨버터 클래스는 @Converter 어노테이션을 사용하고 AttributeConverter 인터페이스를 구현해야 한다. 그리고 제네릭에 현재 타입과 변환할 타입을 지정해야 한다.
여기서는 <Boolean, String>을 지정해서 Boolean 타입을 String 으로 변환한다.
public interface AttributeConverter<X, Y> {
public Y convertToDatabaseColumn(X attribute);
public X convertToEntityAttribute(Y dbData);
}
-
convertToDatabaseColumn : 엔티티의 데이터를 데이터베이스 컬럼에 저장할 데이터로 변환한다.
-
convertToEntityAttribute : 데이터베이스에서 조회한 컬럼 데이터를 엔티티의 데이터로 변환한다.
-
컨버터 클래스 레벨에서 설정
@Entity @Convert(converter=BooleanToYNConverter.class, attributeName = "vip") public class Member {...}
글로벌 설정
모든 Boolean 타입에 컨버터를 적용하려면 @Converter(autoApply = true) 옵션을 적용하면 된다.
@Converter(autoApply = true)
public class BooleanToYNConverter implements AttributeConverter<Boolean, String> {...}
위처럼 글로벌 설정을 하게되면 별도의 @Converter 지정 없이 모든 Boolean 타입에 대해 자동으로 컨버터가 적용된다.
| 속성 | 기능 | 기본 값 |
|---|---|---|
| converter | 사용할 컨버터를 지정 | |
| attributeName | 컨버터를 적용할 필드를 지정 | |
| disableConversion | 글로벌 컨버터나 상속 받은 컨버터를 사용하지 않는다. | false |
리스너
JPA 리스너 기능을 활용하면 엔티티의 생명주기에 따른 이벤트(ex. 삭제 로그 등)를 처리할 수 있다.
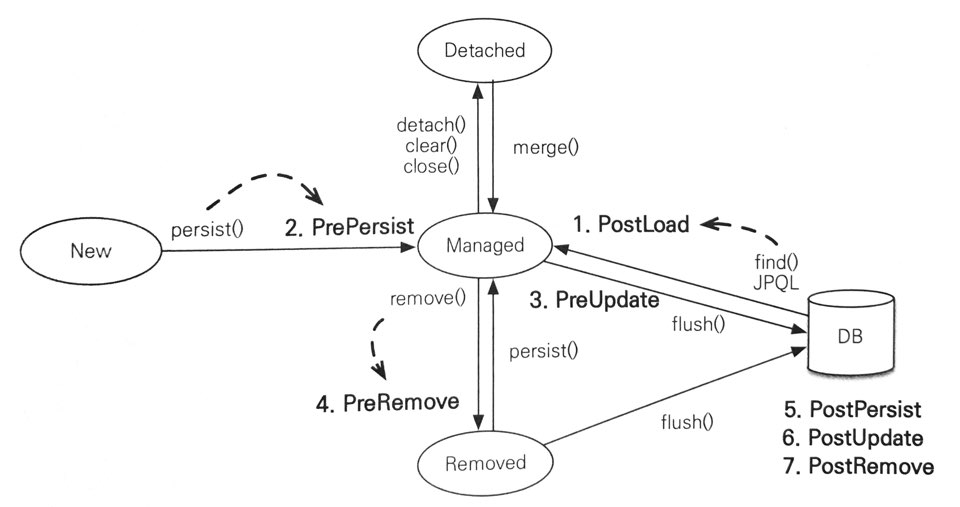
- PostLoad : 엔티티가 영속성 컨텍스트에 조회된 직후 또는 refresh를 호출한 후(2차 캐시에 저장되어 있어도 호출)
- PrePersist : persist() 메소드를 호출해서 엔티티를 영속성 컨텍스트에 관리하기 직전에 호출. 식별자 생성 전략을 사용한 경우, 엔티티에 식별자는 아직 존재하지 않는다. 새로운 인스턴스를 merge할 때도 수행된다.
- PreUpdate : flush나 commit을 호출해서 엔티티를 데이터베이스에 수정하기 직전에 호출.
- PreRemove : remove() 메소드를 호출해서 엔티티를 영속성 컨텍스트에서 삭제하기 직전에 호출. 또한 삭제 명령어로 영속성 전이가 일어날 때도 호출된다. orphanRemoval에 대해서는 flush나 commit시에 호출된다.
- PostPersist : flush나 commit을 호출해서 엔티티를 데이터베이스에 저장한 직후에 호출. 식별자가 항상 존재한다.
PostPersist는 식별자 생성 전략이 IDENTITY면 식별자를 생성하기 위해 persist()를 호출하면서 데이터베이스에 해당 엔티티를 저장하므로 이 때는 persist()를 호출한 직후에 바로 PostPersist가 호출된다.
- PostUpdate : flush나 commit을 호출해서 엔티티를 데이터베이스에 수정한 직후에 호출
- PostRemove : flush나 commit을 호출해서 엔티티를 데이터베이스에 삭제한 직후에 호출
이벤트 적용 위치
이벤트는 엔티티에서 직접 받거나 별도의 리스너를 등록해서 받을 수 있다.
엔티티에 직접 적용
@Entity
public class Duck {
@Id @GeneratedValue
public Long id;
private String name;
@PrePersist
public void prePersist() {
System.out.println("Duck.prePersist id=" + id);
}
public void postPersist() {
System.out.println("Duck.postPersist id=" + id);
}
@PostLoad
public void postLoad() {
System.out.println("Duck.postLoad");
}
@PreRemove
public void preRemove() {
System.out.println("Duck.preRemove");
}
@PostRemove
public void postRemove() {
System.out.println("Duck.postRemove");
}
...
}
해당 엔티티에 이벤트가 발생할 때 마다 어노테이션으로 지정한 메소드가 실행된다.
별도의 리스너 등록
@Entity
@EntityListeners(DuckListener.class)
public class Duck {...}
public class DuckListener {
@PrePersist
// 특정 타입이 확실하면 특정 타입을 받을 수 있다.
private void prePersist(Object obj) {
System.out.println("DuckListener.prePersist obj = [" + obj + "]");
}
@PostPersist
// 특정 타입이 확실하면 특정 타입을 받을 수 있다.
private void postPersist(Object obj) {
System.out.println("DuckListener.postPersist obj = [" + obj + "]");
}
}
리스너는 대상 엔티티를 파라미터로 받을 수 있다. 반환 타입은 void로 설정해야 한다.
기본 리스너 사용
orm.xml에 등록한다.
여러 리스너를 등록했을 때 호출 순서는 다음과 같다.
- 기본 리스너
- 부모 클래스 리스너
- 리스너
- 엔티티
더 세밀한 설정
-
javax.persistence.ExcludeDefaultListeners : 기본 리스너 무시
-
javax.persistence.ExcludeSuperclassListeners : 상위 클래스 이벤트 리스너 무시
-
기타 어노테이션 적용 코드
@Entity
@EntityListeners(DuckListener.class)
@ExcludeDefaultListeners
@ExcludeSuperclassListeners
public class Duck extends BaseEntity {...}
이벤트를 잘 활용하면 대부분의 엔티티에 공통으로 적용하는 등록 일자, 수정 일자 처리와 해당 엔티티를 누가 등록/수정했는지에 대한 기록을 리스너 하나로 처리할 수 있다.
엔티티 그래프
JPA 2.1에 추가된 기능으로 엔티티를 조회하는 시점에 함께 조회할 연관된 엔티티를 선택할 수 있다. 따라서 JPQL은 데이터를 조회하는 기능만 수행하고, 연관된 엔티티를 함께 조회하는 기능은 엔티티 그래프를 사용하면 된다.
엔티티 그래프 기능은 엔티티 조회시점에 연관된 엔티티들을 함께 조회하는 기능이다. 엔티티 그래프는 정적으로 정의하는 Named 엔티티 그래프와 동적으로 정의하는 엔티티 그래프가 있다.
Named 엔티티 그래프
- 주문 조회 시, 연관된 회원도 함께 조회
@NamedEntityGraph(name = "Order.withMember", attributeNodes = {
@NamedAttributeNode("member")
})
@Entity
@Table(name = "ORDERS")
public class Order {
@Id @GeneratedValue
@Column(name = "ORDER_ID")
private Long id'
@ManyToOne(fetch = FetchType.LAZY, optional = false)
@JoinColumn(name = "MEMBER_ID")
private Member member; // 주문 회원
...
}
@NamedEntityGraph로 정의한다.
- name : 엔티티 그래프의 이름을 정의한다.
- attributeNodes : 함께 조회할 속성 선택한다. 이 때, @NamedAttributeNode를 사용하고 그 값으로 함께 조회할 속성을 선택하면 된다.
Order.member가 지연 로딩으로 설정되어있지만, 엔티티 그래프에서 함께 조회할 속성으로 member를 선택했으므로 이 엔티티 그래프를 사용하면 Order를 조회할 때 연관된 member도 함께 조회할 수 있다.
둘 이상 정의하려면 @NamedEntityGraphs를 사용하면 된다.
em.find()에서 엔티티 그래프 사용
- 엔티티 그래프 사용 예제
EntityGraph graph = em.getEntityGraph("Order.withMember");
Map hints = new HashMap();
hints.put("javax.persistence.fetchgraph", graph);
Order order = em.find(Order.class, orderId, hints);
- 실행된 SQL
select o.*, m.*
from
ORDERS o
inner join
Member m
on o.MEMBER_ID=m.MEMBER_ID
where
o.ORDER_ID=?
N+1 문제의 해결책 중 하나가 될 수 있다.
join fetch vs entityGraph 참조 : https://jojoldu.tistory.com/165
참조 : https://blog.leocat.kr/notes/2019/05/26/spring-data-using-entitygraph-to-customize-fetch-graph
subgraph
Order -> OrderItem -> Item 까지 Order가 관리하지 않는 Item 필드까지 조회하기 위해 사용한다.
@NamedEntityGraph(name = "Order.withAll", attributeNodes = {
@NamedAttributeNode("member"),
@NamedAttributeNode(value = "orderItems", subgraph = "orderItems")
},
subgraphs = @NamedSubgraph(name = "orderItems", attributeNodes = {
@NamedAttributeNode("item")
})
)
@Entity
@Table(name = "ORDERS")
public class Order {
@Id @GeneratedValue
@Column(name = "ORDER_ID")
private Long id;
@ManyToOne(fetch = FetchType.LAZY, optional = false)
@JoinColumn(name = "MEMBER_ID")
private Member member; // 주문 회원
@OneToMany(mappedBy = "order", cascade = CascadeType.ALL)
private List<OrderItem> orderItems = new ArrayList<OrderItem>();
...
}
@Entity
@Table(name = "ORDER_ITEM")
public class OrderItem {
@Id @GeneratedValue
@Column(name = "ORDER_ITEM_ID")
private Long id;
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "ITEM_ID")
private Item item; // 주문 상품
...
}
Order.withAll라는 Named 엔티티 그래프를 정의했다. 이 엔티티 그래프는 Order -> Member, Order -> OrderItem, OrderItem -> Item의 객체 그래프를 함께 조회한다.
이 때, OrderItem -> Item 은 Order의 객체 그래프가 아니므로 subgraph 속성으로 정의해야 한다.
Map hints = new HashMap();
hints.put("javax.persistence,fetchgraph", em.getEntityGraph("Order.witAll"));
Order order = em.find(Order.class, orderId, hints);
- 실행된 sql
select o.*, m.*, oi.*, i.*
from
ORDERS o
inner join
Member m
on o.MEMBER_ID=m.MEMBER_ID
left outer join
ORDER_ITEM oi
on o.ORDER_ID=oi.ORDER_ID
left outer join
Item i
on oi.ITEM_ID=i.ITEM_ID
where
o.ORDER_ID=?
JPQL에서 엔티티 그래프 사용
em.find()와 동일하게 힌트만 추가하면 된다.
List<Order> resultList = em.createQuery("select o from Order o where o.id = :orderId", Order.class)
.setParameter("orderId", orderId)
.setHint("javax.persistence.fetchgraph", em.getEntityGraph("Order.withAll"))
.getResultList();
동적 엔티티 그래프
엔티티 그래프를 동적으로 구성하려면 createEntityGraph() 메소드를 사용하면 된다.
EntityGraph<Order> graph = em.createEntityGraph(Order.class); // 동적 엔티티 그래프 생성
graph.addAttributeNodes("member"); // Order.member 속성을 엔티티 그래프에 포함
Map hints = new HashMap();
hints.put("javax.persistence.fetchgraph", graph);
Order order = em.find(Order.class, orderId, hints);
동적 엔티티 그래프 subgraph
EntityGraph<Order> graph = em.createEntityGraph(Order.class);
graph.addAttributeNodes("member");
Subgraph<OrderItem> orderItems = graph.addSubgraph("orderItems"); // 서브그래프 생성
orderItems.addAttributeNodes("item"); // 서브그래프에 item 속성 추가
Map hints = new HashMap();
hints.put("javax.persistence.fetchgraph", graph);
Order order = em.find(Order.class, orderId, hints);
엔티티 그래프 정리
- 엔티티 그래프는 항상 조회하는 엔티티의 ROOT에서 시작해야 한다.
- 영속성 컨텍스트에 해당 엔티티가 이미 로딩되어 있으면 엔티티 그래프가 적용되지 않는다.(아직 초기화되지 않은 프록시에는 엔티티 그래프가 적용된다.)
- fetchgraph vs loadgraph
- fetchgraph : 엔티티 그래프에 선택한 속성만 함께 조회한다.
- loadgraph : 선택한 속성 뿐만 아니라 글로벌 fetch 모드가 FetchType.EAGER로 설정된 연관관계도 포함해서 조회한다.
정리
- 컨버터를 활용함으로써 엔티티의 데이터를 변환하여 바로 데이터베이스에 저장할 수 있다.
- 리스너를 활용함으로써 엔티티에서 발생한 이벤트를 받아 처리할 수 있다.
- 페치 조인은 JPQL을 사용해야 하지만 엔티티 그래프를 활용함으로써 JPQL 대신 원하는 객체 그래프를 한 번에 조회할 수 있다.

Comments